Workshop 06 - Implementing an Artificial Neural Network (ANN)
← Home →Neuron implementation
It is important to mention, the following examples are focused on pedagogy, not on efficiency.
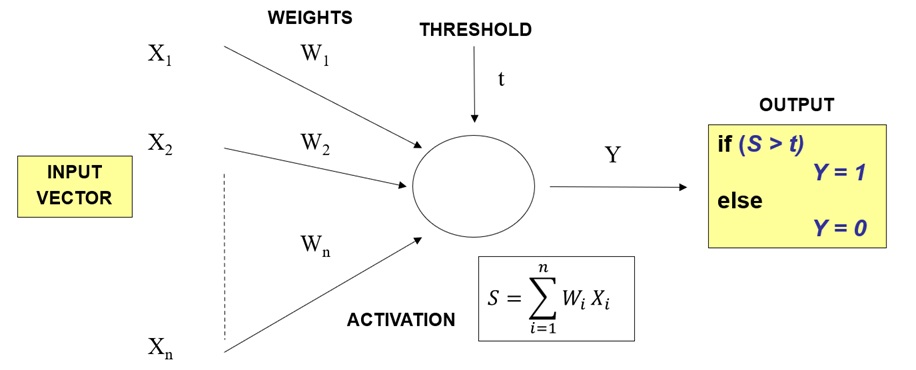
The neuron contains a list of "dendrites" and the activation function, injected using the strategies pattern.
The activation functions instantiation responsibility is delegated to a factory pattern implementation.
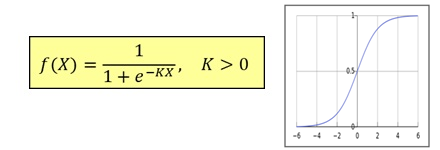
Two activation functions were implemented: Step (Heaviside) and Sigmoid.
The Sigmoid activation function is preferred as it is continuous and differentiable.
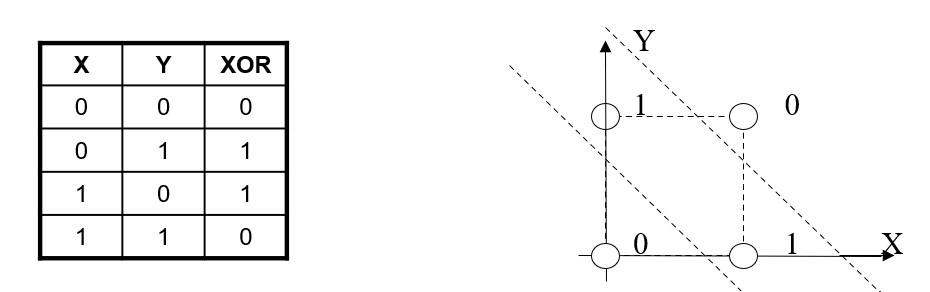
Neurons are separating the hyperspace by a hyperplane.
For example, in 2D, there are an infinite number of solutions for the OR problem:

Neurons are limited to linearly separable problems.
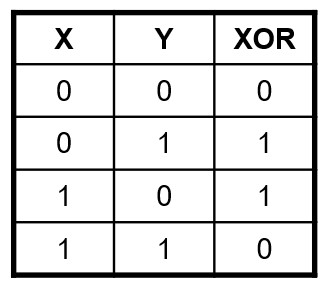
For example, the XOR values cannot be separated by a line.
Multi-Layer Perceptron (MLP) Implementation
For non-linear separable problems (e.g. XOR), one could interconnect multiple neurons (the connectionist paradigm). There are various Artificial Neural Network topologies (e.g. completely interconnected).We'll discuss the Multi-Layer Perceptron => feed-forward ANN composed by locally interconnected neural layers.
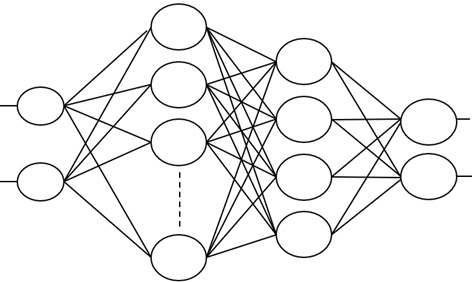
The Layer class represents a set of not connected neurons, with the same input space dimension.
The Layer Enumerator (the Layer class was designed to implement the IEnumerator
MLP is a list of neural layers:
The Backpropagation Training Algorithm
Supervised Learning algorithm => the training set containing labeled data is presented multiple times to the ANN.In the discussed implementation, the training set is represented as a generic list of TrainingObject instances.
The ANN weights are initialized with random small values.
Backpropagation is a gradient descent algorithm => minimizing the classification error = criteria expressed as a function J of all ANN weights.
Requires differentiable activation functions (e.g. Sigmoid).
Risk: getting stuck in a local minimum.
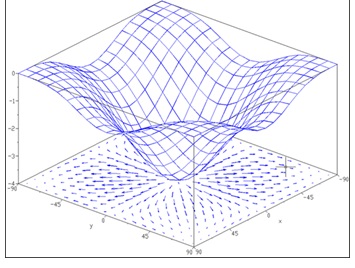
The ANN weights are adjusted from the output to the input layer (back-propagation) proportionally with the anti-gradient of criteria function, J.

For implementing MLP training algorithms one could start from the template design pattern. The TrainingProgress event is used for providing information on training evolution and allows processing intreruption (set Cancel to True).
Backpropagation is inheriting the TrainAlgorithmBase base class.
Example: MLP for XOR
For solving XOR a MLP with 2 layers and 3 neurons is necessary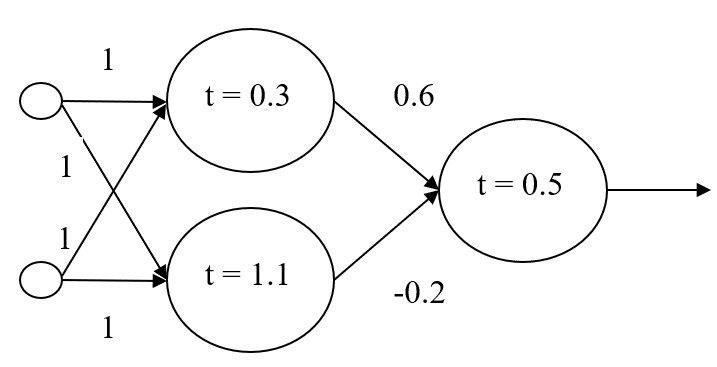
The XOR training set is presented to the ANN multiple times (until the expected error is reached)
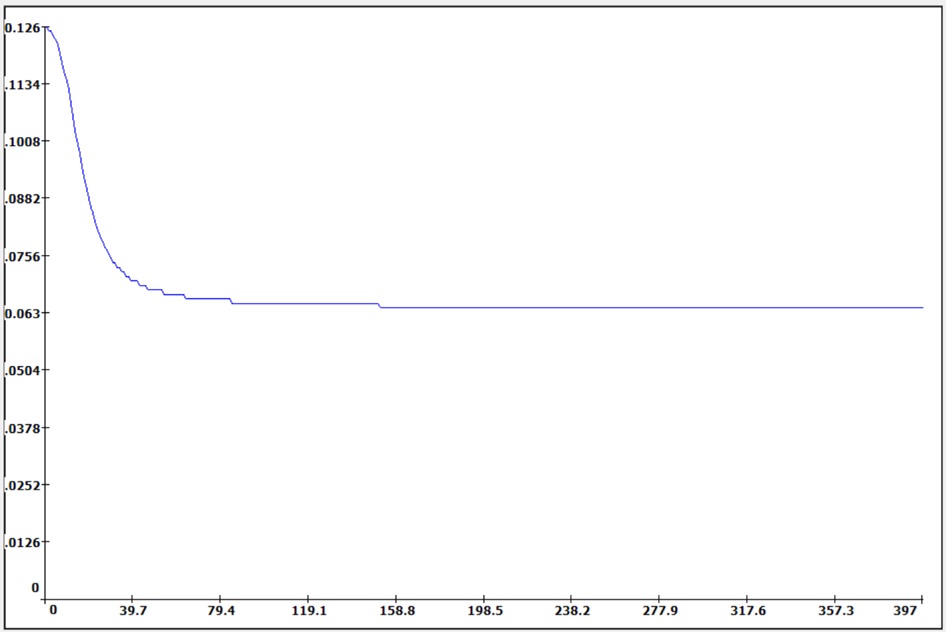
At each step, the neural weights are adjusted proportionally with the anti-gradient of the criteria function J.
The loop ends when the expected value of J is reached.
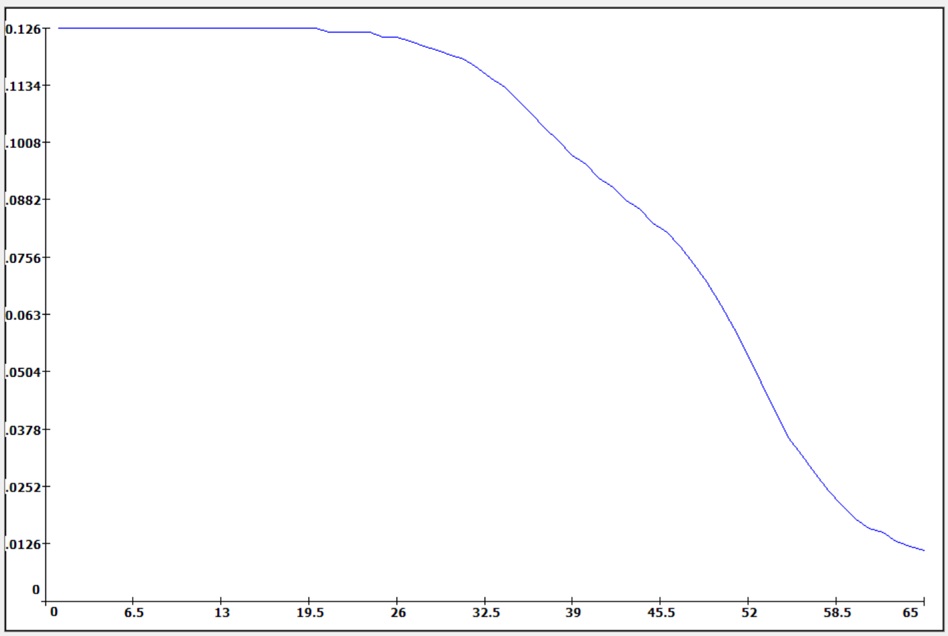
When getting stuck in a local minimum, one possible strategy is relaunching the training process.
References:
D. Dumitrescu, H. Costin, Retele Neuronale Teorie si Aplicatii, Teora, Romania, 1996Single qubit neural quantum circuit for solving Exclusive-OR
← Home →